Action Space Shaping in Deep RL
How should you shape the actions? (2, 3), (3, 2) or (6,)?
- Reference
- Introduction
- Action space shaping
- Action spaces of other games
- Experiments
- Conclusion
- Acknowledgements
This is a presentation of the paper “Action space shaping in Deep Reinforcement Learning”, by Anssi Kanervisto et al., 2020, in IEEE Conference on Games 2020.
Author: Long M. Luu. Contact: minhlong9413@gmail.com or AerysS#5558.
Reference
Action Space Shaping in Deep Reinforcement Learning
Introduction
Take a game that uses keyboard and mouse:
- Too many keys
- Mouse is continuous
Probably hard for human to learn. Should we remove keys? If we remove keys so that it is still playable, should we also remove unnecessary actions?

The question: do these transformations support the training of RL agents?
Environments in this paper: toy environment, Atari, VizDoom, Starcraft II and Obstacle Tower.


Action space shaping
Types of action spaces
There are three common types of actions, established by OpenAI Gym:
-
Discrete. Each action is an integer $a \in {0, 1, …, N}$ where $n \in \mathbb{N}$ represents the number of possible actions.

-
MultiDiscrete. An extension ofDiscrete. Action is a vector of individual discrete actions $a_i \in {0, 1, …, N_i}$, each with possibly different number of possibilities $N_i$. For example, a keyboard is a largeMultiDiscretespace.

-
Continuous. Action $a \in \mathbb{R}$ is a real number/vector.

A set of keyboard buttons and mouse control can be represented as a combination of MultiDiscrete and Continuous.
MultiDiscrete are often treated as independent Discrete decisions. Support for Continuous is often harder to implement correctly than for Discrete space.
Action space shaping in video games
There are three major categories of action space transformation:
-
RA: Remove actions. For example, “Sneak” in Minecraft is not crucial for the game progress ⇒ often removed.RAhelps with exploration since there are less actions to try. However, this requires domain knowledge, and may restrict agent’s capabilities.

-
DC: Discretize continuous actions. Mouse movement or camera turning speed are often discretized by splitting them into a set of bins, or defining as discrete choices: negative, zero, positive. This turning rate is a hyperparameter. If the rate is too high, actions are not fine-grained, so the agents may have difficulties in aiming at a specific spot.

-
CMD: ConvertMultiDiscretetoDiscrete. Assumption: it is easier to learn a single large policy than multiple small policies. For example Q-Learning only works forDiscreteactions.

Action spaces of other games

Experiments
Environments: Atari, VizDoom, Starcraft II, Obstacle Tower challenge.
Algorithm: PPO, IMPALA
Libraries: stable-baselines, rllib.
8 parallel environments.
Get-To-Goal
A simple reach-the-goal env: player and goal start at a random environment. Player tries to reach the goal (reward 1) or when env times out (reward 0). Agent receives a 2D vector pointing towards the goal, and the rotating angle $(cos(\phi), sin(\phi))$ tuple where $\phi \in [0, 2\pi]$. Goal: test DC by using discrete and continuous variants of the action space:
-
MultiDiscrete: four buttons Up, Down, Left, Right. -
Discrete: flatten version of above, but only one button at a time, i.e. no diagonal movements. -
Continuous: player specifies the exact direction of the next move with a continuous value with 0 representing straight up, 90 straight right and 180 straight down. -
Tank, Discrete/MultiDiscrete: player has a heading $\phi$ and it can choose to increase/decrease it (turn left/right) and/or to move forward/backward towards the heading. For tank-like controls, player must stop completely to turn.
Authors also add bogus action (actions that do nothing), and backward and strafe actions.

Strafe action. Camera of blue is locked towards red.
To study RA and CMD, the authors add and/or remove additional actions.


Figure (left): Tank-like control is slower than non-tank. Continuous is slowest. With rllib, observed similar results, except Continuous learned faster than tank-like ⇒ Continuous are sensitive to the implementation.
Figure (right) with and without additional actions ⇒ Agent learns slower the more actions they have (RA).

Figure shows the agent learns faster on MultiDiscrete spaces ⇒ RL agents can profit from MultiDiscrete compared to Discrete. (CMD).
Atari games
Atari games use Discrete spaces, which consists of only necessary actions to play the game (minimal, default in Gym). Authors add more actions: full, and multi-discrete, where joystick and fire-button are additional buttons with 9 and 2 options respectively.

Figure 3 shows no clear difference, except:
- MsPacman. multi-discrete achieved almost one-quarter higher score.
- Enduro: minimal underperforms, despite the fact that the full space does not offer any new actions.
RA can limit performance, but overall does not change results. Same thing applies to CMD.
VizDoom
In increasing difficulty:
- Get-to-goal: Similar to earlier, except it is a first-person shooter scenario. +1 if reaches, 0 otherwise, include one minute of game-time timeout.
- HGS: gather health kits to survive
- Deathmatch: fight against randomly spawn enemies. +1 per kill, one shot.
RA scenarios:
- Bare-minimum: moving forward, turning left, attack (deathmatch).
- Minimal: bare-minimum + turning right.
- Backward: minimal + moving backward.
- Strafe: backward + moving left and right.
Five different spaces for each set:
- Original
MultiDiscrete - Three levels of
CMD. - Continuous mouse control
DC
Observation: grayscale (Get-to-goal and HGS), RGB (Deathmatch) of size 80x60 + game variables.



From figure, MultiDiscrete performs as well as discretized version (CMD). Continuous action prevents learning in most spaces (DC). Increasing the number of actions improves the results in difficult cases (RA).
Obstacle Tower
3D platform game with randomly generated levels. Original space is MultiDiscrete with options to move forward/backward and left/right, turn left/right and jump.
To test CMD and RA, authors disabled strafing, moving backward or forcing moving forward.
Discrete is obtained by creating all possible combinations of MultiDiscrete.
Observation: 84x84 RGB image.


From figure, no significant difference between two sets, except Backward action shows slower learning than the rest ⇒ Intuition to remove unnecessary actions.
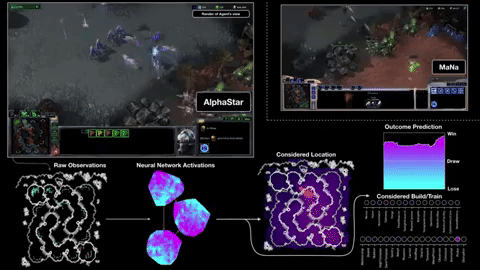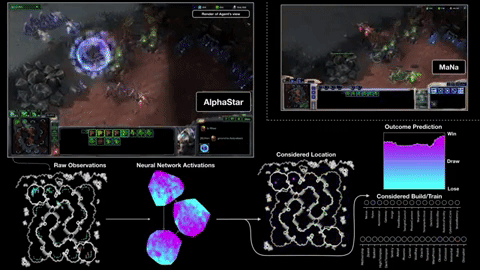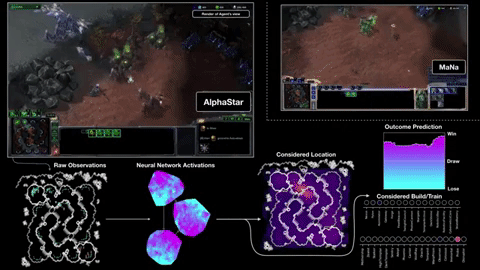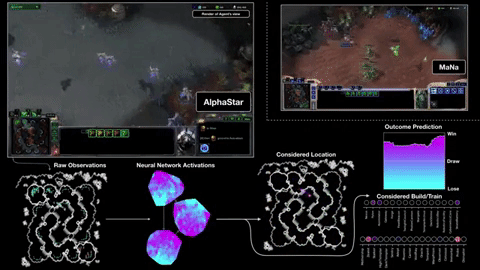
Starcraft II
From figure Action masking is crucial in BM and CMAG. On BM, RA can lead to significant improvement.


Conclusion
Removing actions RA can lower the overall performance (VizDoom) but can be an important step to make environments learnable (SC2, Obstacle Tower).
Continuous are harder to learn than discrete and can also prevent learning. Discretizing them DC improves performance notably.
In Get-To-Goal, MultiDiscrete scales well with an increasing number of actions, while Discrete does not. There is no significant different in other environments.
In short: use MultiDiscrete > Discrete > Continuous.
Start by removing all but the necessary actions and discretizing all continuous actions. Avoid turning multi-discrete actions into a single discrete action and limit the number of choices per discrete action. If the agent is able to learn, start adding removed actions for improved performance, if necessary.
Acknowledgements
Thanks Anssi Kanervisto for reviewing this document.